from: http://abloz.com
author:周海汉
date:2012.7.3
一、lucene,solr,nutch,hadoop的区别和联系
apache lucene是apache下一个著名的开源搜索引擎内核,基于Java技术,处理索引,拼写检查,点击高亮和其他分析,分词等技术。
nutch和solr原来都是lucene下的子项目。但后来nutch独立成为独立项目。nutch是2004年由俄勒冈州立大学开源实验室模仿google搜索引擎创立的开源搜索引擎,后归于apache旗下。nutch主要完成抓取,提取内容等工作。
solr则是基于lucene的搜索界面。提供XML/HTTP 和 JSON/Python/Ruby API,提供搜索入口,点击高亮,缓存,备份和管理界面。
hadoop原来是nutch下的分布式任务子项目,现在也成为apache下的顶级项目。nutch可以利用hadoop进行分布式多任务抓取和分析存储工作。
所以,lucene,nutch,solr,hadoop一起工作,是能完成一个中型的搜索引擎工作的。
前面有一篇《apache 搜索引擎solr试用》,详细描述了单独的solr实现搜索界面的示例。
下面的部分,基于nutch,完成网页的抓取,并通过solr完成索引和搜索,实现真正的完整的搜索引擎建立流程。
二、下载安装nutch
下载页面:
http://www.apache.org/dyn/closer.cgi/nutch/
[zhouhh@Hadoop48 ~]$ wget http://labs.renren.com/apache-mirror/nutch/apache-nutch-1.5-bin.tar.gz
Length: 46293852 (44M) [application/x-gzip]
http://wiki.apache.org/nutch/NutchTutorial
安装
[zhouhh@Hadoop48 ~]$ mkdir nutch
[zhouhh@Hadoop48 ~]$ mv apache-nutch-1.5-bin.tar.gz nutch/
[zhouhh@Hadoop48 ~]$ cd nutch/
[zhouhh@Hadoop48 nutch]$ tar zxvf apache-nutch-1.5-bin.tar.gz
[zhouhh@Hadoop48 bin]$ chmod +x nutch
否则会出Permission denied错误。
将nutch加入PATH环境变量中。
[zhouhh@Hadoop48 ~]$ vi .bashrc
export NUTCH_HOME=/home/zhouhh/nutch
export PATH=$PATH:$NUTCH_HOME/bin
执行
[zhouhh@Hadoop48 ~]$ nutch
Usage: nutch [-core] COMMAND
三、抓取第一个网站
假如我想抓取http://guodo.net 修改抓取url正则,仅允许抓guodo.net上的内容。
[zhouhh@Hadoop48 nutch]$ vi conf/regex-urlfilter.txt
修改+.
# accept anything else
#+.
为
+^http://([a-z0-9]*.)*guodo.net/
新建urls目录,用于存放首要抓取的url列表,我们存放http://guodo.net
[zhouhh@Hadoop48 nutch]$ mkdir urls
[zhouhh@Hadoop48 urls]$ vi seed.txt
http://guodo.net
给爬行蜘蛛取个名字
[zhouhh@Hadoop48 conf]$ cat nutch-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>http.agent.name</name>
<value>abloz.com's Nutch Spider</value>
</property>
</configuration>
启动solr
[zhouhh@Hadoop48 example]$ pwd
/home/zhouhh/apache-solr-4.0.0-ALPHA/example
[zhouhh@Hadoop48 example]$ java -jar start.jar
http://hadoop48:8983/solr/#/
将nutch的schema替换原solr自带的schema,便于搜索
[zhouhh@Hadoop48 nutch]$ cp conf/schema-solr4.xml ../apache-solr-4.0.0-ALPHA/example/solr/conf/.
zhouhh@Hadoop48 nutch]$ cd ../apache-solr-4.0.0-ALPHA/example/solr/conf/.
备份原来的索引schema,用nutch的schema替代
[zhouhh@Hadoop48 conf]$ mv schema.xml schema.xml.bk
[zhouhh@Hadoop48 conf]$ mv schema-solr4.xml schema.xml
此时执行抓取,由于版本问题,会返回错误
[zhouhh@Hadoop48 nutch]$ nutch crawl urls -solr http://Hadoop48:8983/solr/ -depth 3 -topN 5
java.lang.RuntimeException: Can't find resource
: 'stopwords_en.txt' in classpath or 'solr/./conf/'
替换语言资源位置到lang下。
[zhouhh@Hadoop48 conf]$ vi schema.xml
:%s/"stopwords_en.txt"/"lang/stopwords_en.txt"/g
抓取数据 仅抓取:
[zhouhh@Hadoop48 nutch]$ nutch crawl urls -dir crawl -depth 3 -topN 5
-dir 放置爬行结果的目录
-threads 并行抓取线程数
-depth 指示从首页往下爬行链接的深度
-topN N 指示每层返回的最大页数
爬行完,看到crawl多了几个目录
[zhouhh@Hadoop48 nutch]$ ls crawl
crawldb linkdb segments
抓取并通过solr查询
[zhouhh@Hadoop48 nutch]$ nutch crawl urls -solr http://Hadoop48:8983/solr/ -depth 3 -topN 5
Injector: starting at 2012-09-17 15:51:04
Injector: crawlDb: crawl/crawldb
Injector: urlDir: urls
...
LinkDb: merging with existing linkdb: crawl/linkdb
LinkDb: finished at 2012-09-17 15:55:11, elapsed: 00:00:25
crawl finished: crawl
建立索引
[zhouhh@Hadoop48 nutch]$ nutch solrindex http://hadoop48:8983/solr/ crawl/crawldb -linkdb crawl/linkdb crawl/segments/*
SolrIndexer: starting at 2012-09-17 16:06:27
Indexing 13 documents
SolrIndexer: finished at 2012-09-17 16:07:50, elapsed: 00:01:23
建立索引工作时能看到SolrIndexer作为Hadoop Job在工作。
[zhouhh@Hadoop48 ~]$ jps
27771 SecondaryNameNode
27577 NameNode
27863 JobTracker
10684 Jps
10186 jar
10542 SolrIndexer
查询
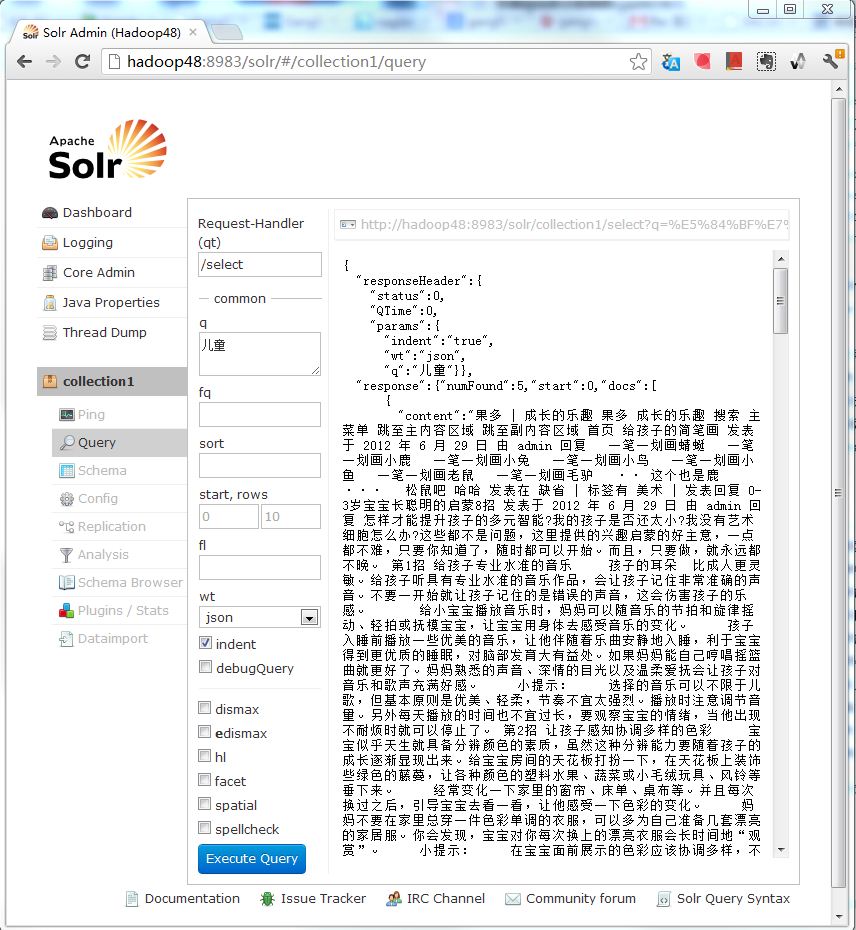
用浏览器进入http://hadoop48:8983/solr/#/collection1/query
在q里面输入“儿童”,可以得到相应查询结果。
如非注明转载, 均为原创. 本站遵循知识共享CC协议,转载请注明来源