简介
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。 Spark由UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室) 于2009年开始开发并开源. 目前是apache顶级项目.
spark 支持scala,java,python,R. 于 2017年5月发布2.1.1版本.
建议最好使用scala语言来开发. 因为java和python版本经常跟不上spark的进度. java,python语言还会有各种数据转换.
spark 组成部分
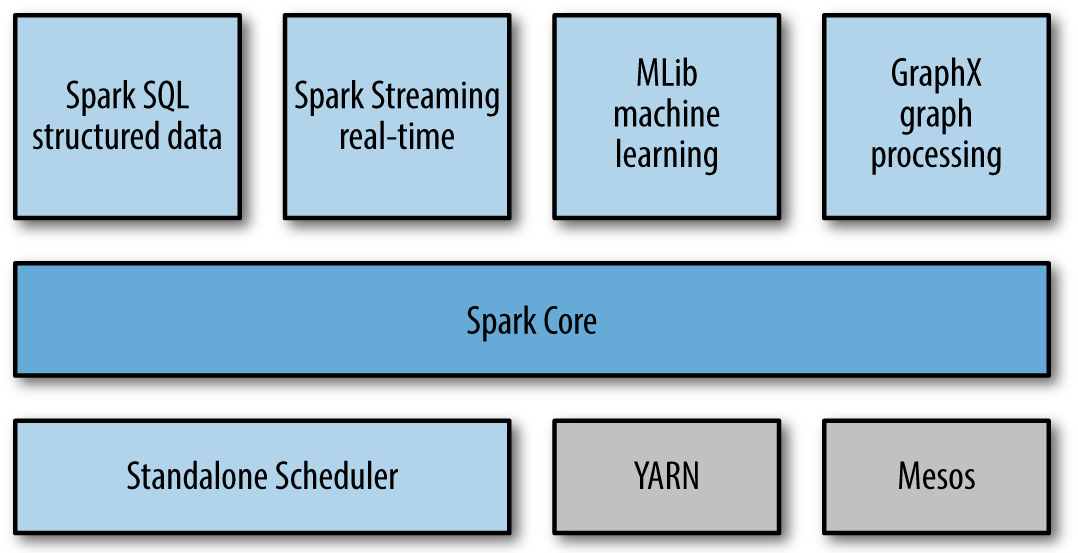
spark core
spark 的基础, 包括任务计划, 内存管理, 容错处理, 存储管理等, 同时也是resilient distributed datasets (RDD)的定义的地方. RDD表示spark可以在多台设备中进行分布式处理的数据集.
spark sql
spark sql 是spark管理结构化数据的包. 提供SQL查询接口. 兼容Apache Hive Sql 语言(HQL). 支持各种数据源, 如Hive 表,Parquet,Json格式. 支持sql查询的数据和各种编程RDD数据混合使用.
spark sql 是 加州大学伯克利分校的shark的替代品.
spark streaming
spark streaming 是spark 处理实时数据流的组件. 它提供api操作流式数据, 使其符合RDD的格式要求.
MLlib
提供通用机器学习算法,包括分类,回归,聚类和协同过滤, 模型评估和数据导入功能. 还有梯度下降优化算法等基础功能.
所有算法支持分布式扩容.
GraphX
GraphX 是提供图操作的组件. 如处理社交网络的朋友关系网络图. 实现并发图计算. 扩展了RDD api, 以直接创建图的节点和边, 并且各附带不同的属性. GraphX还提供图操作的各种方法(如subgraph 和 mapVertices), 以及通用图算法库,如pagerank和三角计算.
集群管理
Spark 支持从一台节点到数千台节点的设备运算. 对单台的设备, 通过自身携带的Standalone Scheduler管理. 对多台设备, 通过Hadoop YARN, Apache Mesos来管理集群.
Spark 下载安装
spark独立程序
spark 独立程序必须对SparkContext进行初始化. 如scala和java相关包可以通过maven等进行管理. 可以通过mvnrepository 查到相关依赖.
maven
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.1.1</version>
<scope>provided</scope>
</dependency>
gradle
provided group: 'org.apache.spark', name: 'spark-core_2.11', version: '2.1.1'
provided group: 'org.apache.spark', name: 'spark-sql_2.11', version: '2.1.1'
provided group: 'org.apache.spark', name: 'spark-streaming_2.11', version: '2.1.1'
provided group: 'org.apache.spark', name: 'spark-mllib_2.11', version: '2.1.1'
sbt
libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "2.1.1" % "provided"
libraryDependencies += "org.apache.spark" % "spark-sql_2.11" % "2.1.1" % "provided"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.1.1" % "provided"
libraryDependencies += "org.apache.spark" % "spark-mllib_2.11" % "2.1.1" % "provided"
初始化代码
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
val conf = new SparkConf().setMaster("local").setAppName("My App")
val sc = new SparkContext(conf)
- setMaster 如何连接集群,示例是”local”本地.
- setAppName 用于标识在集群中运行的名字, 会在监测UI上看到.
停止程序
可以调用SparkContext的stop(),也可以用system.exit(0),sys.exit(0)等.
测试
可以用maven或sbt 示例是一个单词计数.
单词计数代码
/* wordcount.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val logFile = "/Users/zhouhh/spark/README.md"
val outputFile = "/Users/zhouhh/wc.txt"
val conf = new SparkConf().setAppName("Word count")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val words = logData.flatMap(line => line.split(" "))
val wordsmap = words.map(w => (w,1))
val wordcount = wordsmap.reduceByKey(_ + _) //reduceByKey{case (x, y) => x + y}
wordcount.saveAsTextFile(outputFile)
}
}
编写sbt文件
name := "wordcount spark"
version := "0.0.1"
scalaVersion := "2.12.2"
// additional libraries
libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "2.1.1" % "provided"
设置sbt 国内镜像
中心maven库http://repo1.maven.org/maven2/国内访问非常慢, 经常被断开,几乎到不可用状态. 阿里云的镜像算是造福广大码农了.
zhouhh@/Users/zhouhh/.sbt $ vi repositories
[repositories]
local
aliyun: http://maven.aliyun.com/nexus/content/groups/public/
central: http://repo1.maven.org/maven2/
配置文件解释顺序是:本地->阿里云镜像->Maven主镜像。
编译
zhouhh@/Users/zhouhh/test/spark/wordcount $ sbt package
[info] Set current project to wordcount spark (in build file:/Users/zhouhh/test/spark/wordcount/)
[info] Compiling 1 Scala source to /Users/zhouhh/test/spark/wordcount/target/scala-2.12/classes...
[info] Packaging /Users/zhouhh/test/spark/wordcount/target/scala-2.12/wordcount-spark_2.12-0.0.1.jar ...
[info] Done packaging.
[success] Total time: 8 s, completed 2017-7-1 23:43:35
提交
zhouhh@/Users/zhouhh/test/spark/wordcount $ spark-submit --class WordCount --master local target/scala-2.12/wordcount-spark_2.12-0.0.1.jar
...
Exception in thread "main" java.lang.BootstrapMethodError: java.lang.NoClassDefFoundError: scala/runtime/java8/JFunction2$mcIII$sp
at WordCount$.main(wordcount.scala:15)
at WordCount.main(wordcount.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:743)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:187)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:212)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:126)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.NoClassDefFoundError: scala/runtime/java8/JFunction2$mcIII$sp
这是spark带的scala库比较旧(2.11.8), 系统安装的安装scala比较新(2.12.2)引起的问题.
zhouhh@/Users/zhouhh/test/spark/wordcount $ ls $SPARK_HOME/jars
scala-compiler-2.11.8.jar
scala-library-2.11.8.jar
scala-reflect-2.11.8.jar
scala-xml_2.11-1.0.2.jar
scalap-2.11.8.jar
scala-parser-combinators_2.11-1.0.4.jar
zhouhh@/Users/zhouhh/test/spark/wordcount $ scala -version
Scala code runner version 2.12.2 -- Copyright 2002-2017, LAMP/EPFL and Lightbend, Inc.
修改build.sbt
zhouhh@/Users/zhouhh/test/spark/wordcount $ vi build.sbt
scalaVersion := "2.11.8"
重新编译提交到spark
zhouhh@/Users/zhouhh/test/spark/wordcount $ sbt clean package
zhouhh@/Users/zhouhh/test/spark/wordcount $ spark-submit --class WordCount --master local target/scala-2.11/wordcount-spark_2.11-0.0.1.jar
执行结果
zhouhh@/Users/zhouhh/test/spark/wordcount $ ls ~/wc.txt
_SUCCESS part-00000 part-00001
zhouhh@/Users/zhouhh/test/spark/wordcount $ head -10 ~/wc.txt/part-00000
(package,1)
(this,1)
(Version"](http://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version),1)
(Because,1)
(Python,2)
(page](http://spark.apache.org/documentation.html).,1)
(cluster.,1)
(its,1)
([run,1)
(general,3)
参考
《learning spark》
如非注明转载, 均为原创. 本站遵循知识共享CC协议,转载请注明来源